'인공지능'을 공부하면서 배웠던 내용을 활용해 진행했던 프로젝트를 포스팅해보고자 한다.
팀원들과 함께 실용적으로 사용될 수 있는 AI 앱을 구현해보고자, 실용성이 있는 주제에 대해 고민했다.
그리하여, 이번에는 '음성 인식을 통해 응급 상황을 감지하고 경고를 해줄 수 있는 AI 앱'을 구축하기로 했다.
해당 앱은 공중 화장실에서의 응급상황을 인지하는데 사용한다고 가정하였다.
<Part1> 사용할 데이터
이번에 사용할 데이터는 AI-Hub 사이트에서 제공하는 '위급상황 음성/음향' 데이터이다.
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
www.aihub.or.kr
제공되는 전체 데이터를 사용하고 싶었으나, 팀원 모두 컴퓨터의 용량이 부족해서 샘플 데이터를 사용해서 AI학습을 진행하기로 했다. 또한 모든 상황이 아닌 '폭력범죄', '실내', '실외', '강제추행' 등 공중화장실에서 일어날 수 있는 상황만을 가져와 사용했다.
<Part2> 음성데이터 가공 이론 공부
음성데이터는 시간과 주파수의 특징을 가진다. 좋은 성능을 내는 모델을 구축하기 위해 우리는 음성 데이터를 음성이 가지는 특성을 나타내는 feature로 나타내어야 한다.
# Sampling“ & ”Quantization“
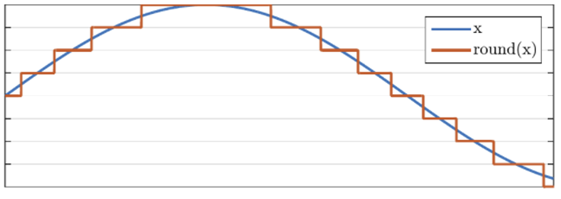
우선, 우리가 쓸 음성데이터는 연속형 데이터이다. 이를 딥러닝에 input으로 넣기 위해서는 Analog digital conversion 과정을 통해 이산형 데이터로 만들어 주어야 한다. 이 과정은 ‘Sampling’과 ‘Quantization’으로 이루어져 있다. 연속적인 데이터를 sample rate의 개수만큼 데이터를 추출하고, “Quantization“으로 연속적인 값들을 이산형 데이터로 바꾸어 준다. 위의 그림처럼 연속적인 파란색 신호는 빨간색의 이산형 신호로 바뀐다.
# STFT
(1) ”Windowing“
음성데이터는 time dependent한 데이터이므로, 이 특성을 살리기 위해 먼저 이산형으로 나타내진 음성 신호들을 20-40ms의 간격으로 나누어 준다. 사람의 음성은 20-40ms 시간 내에 현재 말하고 있는 발음을 바꿀 수 없다는 연구결과에 따라, 해당 구간 내에서는 시간에 따른 음성 특징이 없다고 가정한다.
Windowing 과정을 통해 쪼개진 음성은 더 이상 시간에 의존하지 않으며, 수많은 frequency가 섞여 있는 상태이다. 따라서 이에 푸리에 변환을 한 후 절대값을 해줌으로써 time domain에서 frequency domain으로 바꾸어 준다. 이를 통해 우리는 해당 구간 내에 시간적 특성은 없지만 주파수별 특징을 가지는 값을 가질 수 있다. 또한 이러한 값을 spectrogram이라고 한다. 여기까지의 과정을 STFT라고 하며, 이를 통해 시간적 특성과 주파수별 특성을 모두 가지는 특징을 추출해 낼 수 있다.
(3) "Mel-spectrogram"
마지막으로 STFT로 추출한 데이터에 Mel Filter를 적용하여 mel-spectrogram을 구현한다. Mel Scale은 사람의 청각기관을 모델링하여 표현한 것인데, Mel-filter를 적용함으로써 mel-scale로 spectrogram을 바꿔 최종적으로 학습에 이용한 mel-spectrogram 특징을 추출해 낸다.
AI-Hub에서 제공하는 음성데이터에 대한 정답 label은 JSON파일로 주어졌기 때문에 해당 파일이 어떤 구성으로 되어있는 지 파악한 후 정답 레이블을 가져왔다.
<Part4> DNN 학습
우리는 먼저 colab에서 DNN 방법으로 인공지능을 구현해 보았다.
이 때는 <Part2> 내용에 추가로, 데이터 가공을 한가지 더 해주었다. 각 구간별 mel-spectrogram은 그 구간의 주파수를 나타내는 여러 겂으로 이루어져 있다. 그 구간의 주파수의 평균값을 구해 해당 구간을 대표할 값으로 정해줬다. 그 후, 구간별 mel-spectrogram의 평균값을 다시 시간 순서대로 이어 붙였다.
아래의 코드는 해당 방식으로 음성데이터를 전처리하는 코드이다.
mel_list = []
sound = glob.glob('/content/gdrive/MyDrive/10000/sample/*.wav')
for fname in sound:
X, sample_rate = librosa.load(fname, sr=22050)
spectrogram=abs(librosa.stft(y=X,n_fft=512))
spectrogram_feature = np.mean(spectrogram,axis=1).reshape(1,-1)
power_spectrogram=spectrogram*spectrogram
mel_spectrogram=librosa.feature.melspectrogram(S=power_spectrogram)
power_magnitude=librosa.power_to_db(mel_spectrogram)
mel_spectrogram_feature=np.mean(power_magnitude,axis=1).reshape(1,-1)
MFCC = librosa.feature.mfcc(S = power_spectrogram, n_mfcc=100)
mfcc_feature = np.mean(MFCC,axis = 1).reshape(1,-1)
mel_list.append(mfcc_feature.reshape(-1,))그 후 <part3>에서 말한 것처럼 label 값을 가져온 후, 학습을 위해 label값들을 모두 수치화시켜주었다.
import json
import glob
label_list = []
label = glob.glob('/content/gdrive/MyDrive/10000/sample_json/*.json')
for label_path in label:
with open(label_path,'r',encoding="UTF-8") as f:
json_data = json.load(f)
#print(json.dumps(json_data,indent = "\t",ensure_ascii=False))
One = json_data['annotations'][0]['categories']['category_02']
label_list.append(One)
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
y_data = le.fit_transform(y_data)
데이터 전처리가 끝났으므로 DNN 코드를 구현한 후, 인공지능을 학습시켰다.
정확성을 판단해보기 위해 test 데이터와 train 데이터를 나누어줬다.
DNN 코드는 아래와 같다.
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.33, random_state=42, stratify = y_data)
import torch
import random
import torch.cuda
import torch.utils.data as data
#device = 'cuda'
torch.manual_seed(1)
random.seed(1)
torch.cuda.manual_seed_all(1)
x_train = torch.FloatTensor(x_train)
x_test = torch.FloatTensor(x_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
dataset = data.TensorDataset(x_train,y_train)
#parameters
batch_size = 100
epoch = 500
lr = 0.0001
p = 0.2
dataloader = data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
linear1 = torch.nn.Linear(100, 300, bias = True)
linear2 = torch.nn.Linear(300, 300, bias = True)
linear3 = torch.nn.Linear(300, 300, bias = True)
linear4 = torch.nn.Linear(300, 300, bias = True)
linear5 = torch.nn.Linear(300, 16, bias = True)
relu = torch.nn.ReLU()
drop = torch.nn.Dropout(p = p)
torch.nn.init.xavier_normal_(linear1.weight)
torch.nn.init.xavier_normal_(linear2.weight)
torch.nn.init.xavier_normal_(linear3.weight)
torch.nn.init.xavier_normal_(linear4.weight)
torch.nn.init.xavier_normal_(linear5.weight)
model = torch.nn.Sequential(linear1, relu, drop, linear2, relu, drop, linear3, relu, drop, linear4, relu, drop, linear5)#.to(device)
loss = torch.nn.CrossEntropyLoss()#.to(device)
optim = torch.optim.Adam(model.parameters(),lr = lr)
L = len(dataloader)
model.train()
for i in range(epoch+1):
cost_s = 0
for x, y in dataloader:
X = x#.to(device)
Y = y#.to(device)
optim.zero_grad()
hypo = model(X)
cost = loss(hypo,Y)
cost.backward()
optim.step()
cost_s += cost.item()
cost_avg = cost_s / L
print(i, cost_avg)
with torch.no_grad():
model.eval()
X = x_test#.to(device)
hypo = model(X)
print(hypo)
hypo = torch.nn.functional.softmax(hypo,dim = 1)
y_pred = torch.argmax(hypo, dim=1)응급상황인지 아닌지를 판단하면 되기 때문에, 응급 상황이 아닌 '실내'와 '실외'를 0로 바꾸어 주고 나머지 응급상황은 1로 바꾸어줬다. 그 후 얼마나 정확성이 있는지 확인해보니, 82%로 굉장히 낮았다.

이 방식은 제대로 검출을 못한다고 판단하여, 인공지능 학습 방식을 바꾸기로 했다.
<Part5> CNN 학습
mel-spectrogram의 평균을 구하지 않고 구간별 mel-spectrogram의 값을 모두 사용하기 위해, 2D데이터의 특징을 살려서 학습시킬 수 있는 CNN을 선택하였다. row는 쪼개진 구간으로 이루어져 있으며, column은 해당 구간의 mel-spectrogram으로 이루어져있다. <part2>에서 내용만큼 전처리를 해주었으며, 해당 모델 구현은 pycharm에서 했다.
mel_list = []
sound = glob.glob('C:\\Users\\USER\\Desktop\\sample\\*.wav',recursive=True)
i = 1
for fname in sound:
i += 1
audio_signal, sample_rate = librosa.load(fname, duration=10, sr=48000)
# print(len(audio_signal))
signal = np.zeros(int(48000 * 10 + 1, ))
signal[:len(audio_signal)] = audio_signal
mel_spec = librosa.feature.melspectrogram(y=signal,
sr=48000,
n_fft=1024,
win_length=512,
window='hamming',
hop_length=256,
n_mels=128,
fmax=sample_rate / 2
)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
mel_list.append(mel_spec_db)
이후, mel-spectrogram에 standard scaler를 적용시켜 학습효과를 높이려 하였다.
AI가 구현된 후 사용될 때 들어오는 음성 데이터에도 동일한 scaler를 적용시켜주어야 하기 때문에 dump를 사용하여 저장시켜주었다.
from sklearn.preprocessing import StandardScaler
x_train = np.expand_dims(mel_list, 1) #DataNum, 1ch, H, W
scaler = StandardScaler()
b,c,h,w = x_train.shape
x_train = np.reshape(x_train, newshape=(b,-1))
x_train = scaler.fit_transform(x_train)
x_train = np.reshape(x_train, newshape=(b,c,h,w))
x_train = np.reshape(x_train, newshape=(b,h,w,c))
import joblib
# 객체를 pickled binary file 형태로 저장한다
file_name = 'scaler.pkl'
joblib.dump(scaler, file_name)label 값을 불러오는 코드은 DNN에서와 동일하게 구현했고, 추가로 학습 전 실외와 실내를 1로, 나머지 응급상황을 0으로 바꾸어주었다. 또한 전체 데이터를 train 데이터와 test 데이터로 나누어 학습이 제대로 되었는지 확인해주었다.
#################################
y_data = np.array(label_list)
################################
y_data[y_data=='실외'] = 1
y_data[y_data=='실내'] = 1
y_data[y_data!='1'] = 0
y_data = y_data.astype(int)
print(y_data)
######################################
x_train, x_test, y_train, y_test = train_test_split(x_train, y_data, test_size=0.33, random_state=42, stratify = y_data)
######################################
CNN 모델을 구현할때 해당 모델을 저장하기 위해 keras를 사용하였다.
위험 상황과 일반 상황을 구분하는 이진 분류이므로 loss 함수는 binary crossentropy를 사용했으며, 학습 방법은 Adam을 사용했다.
import random
random.seed(1)
x_train = x_train.astype('float')
x_test = x_test.astype('float')
y_train = y_train.astype('int')
y_test = y_test.astype('int')
#############################
# parameters
batch_size = 100
epoch = 5
lr = 0.00005
p = 0.2
import keras
import tensorflow
model = keras.models.Sequential()
model.add(keras.layers.Activation('relu'))
model.add(keras.layers.Conv2D(16,
kernel_size=3,
strides=(1,1),
padding="same",
input_shape = (128, 1876, 1)
))
model.add(keras.layers.BatchNormalization(axis = 1))
model.add(keras.layers.MaxPooling2D(pool_size=2, strides=(2,2)))
model.add(keras.layers.Dropout(rate=0.3))
model.add(keras.layers.Conv2D(32,
kernel_size=3,
strides=(1,1),
padding="same"
))
model.add(keras.layers.BatchNormalization(axis = 1))
model.add(keras.layers.MaxPooling2D(pool_size=4, strides=(4,4)))
model.add(keras.layers.Conv2D(64,
kernel_size=3,
strides=(1,1),
padding="same"
))
model.add(keras.layers.BatchNormalization(axis = 1))
model.add(keras.layers.Conv2D(128,
kernel_size=3,
strides=(1,1),
padding="same"
))
model.add(keras.layers.BatchNormalization(axis = 1))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(1, use_bias=True,kernel_initializer=keras.initializers.lecun_normal()))
model.add(keras.layers.Activation('sigmoid'))
#############################
model.compile(loss='binary_crossentropy',optimizer='Adam',metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=100, epochs=2)
scores = model.evaluate(x_test,y_test)
print("score : ", scores)
y_pred = model.predict(x_test)
print("y_pred = ",y_pred)
print("answer = ",y_test)
pred = y_pred.reshape((1,-1))
pred.astype('int')
print(pred == y_test)
model.summary()
from keras.models import load_model
model.save('model.h5')
###############################해당 모델은 99%의 높은 성능을 보였고, 우리는 이 모델를 사용하기로 했다!

<Part6> 안드로이드 앱과 통신
성공적으로 AI 모델을 구현했으므로, 이제 안드로이드 앱과의 통신만이 남았다.
컴퓨터 네트워크에서 배운 socket을 활용했다.
앱과 통신이 이루어진 후, 현재 들리는 소리를 5초간 녹음한다. 녹음한 음성 데이터를 인공지능 학습 데이터와 같이 전처리 해주기 위해 <Part5>에서 저장했던 scaler를 불러와 전처리 작업을 해주었다. 그 후 저장해놓았던 인공지능 모델을 가져와 들어온 데이터에 대한 예측값을 반환시키도록 했다. 마지막으로 예측값을 안드로이드 앱에 전송시켜준다.
## 통신 시작
from socket import *
HOST = ""
PORT = 12000
s = socket(AF_INET, SOCK_STREAM)
print ('Socket created')
s.bind((HOST, PORT))
print ('Socket bind complete')
s.listen(1)
print ('Socket now listening')
conn, addr = s.accept()
print("Connected by ", addr)
# 현재 상황 소리 녹음 후 저장
import pyaudio
import wave
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE/CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
# stop Recording
stream.stop_stream()
stream.close()
audio.terminate()
WAVE_OUTPUT_FILENAME = "file.wav"
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
waveFile.close()
## 저장했던 인공지능 모델 불러오기
from keras.models import load_model
model = load_model('C:\\Users\\USER\\PycharmProjects\\pythonProject\\Project_Final\\model.h5')
## 학습 시 사용했던 scaler 불러오기
import joblib
file_name = 'C:\\Users\\USER\\PycharmProjects\\pythonProject\\AI_model\\scaler.pkl'
scaler = joblib.load(file_name)
model.summary()
# 녹음된 음성 불러오기
import tensorflow
path = "C:\\Users\\USER\\PycharmProjects\\pythonProject\\Project_Final"
fname = "\\file.wav"
# 녹음된 음성 데이터 전처리
import librosa
import numpy as np
audio_signal, sample_rate = librosa.load(path+fname, duration=10, sr=48000)
signal = np.zeros(int(48000 * 10 + 1, ))
signal[:len(audio_signal)] = audio_signal
mel_spec = librosa.feature.melspectrogram(y=signal,
sr=48000,
n_fft=1024,
win_length=512,
window='hamming',
hop_length=256,
n_mels=128,
fmax=sample_rate / 2
)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
print(mel_spec_db.shape)
h, w = mel_spec_db.shape
x_train = np.reshape(mel_spec_db, newshape=(1,-1))
print(x_train.shape)
x_train = scaler.transform(x_train)
print(x_train.shape)
x_train = np.reshape(x_train, newshape=(1,1,h,w))
print(x_train.shape)
now = np.reshape(x_train, newshape=(1,h,w,1))
print(now.shape)
print(now)
## 현재 음성 데이터에 대한 예측값 반환
predict = model.predict(now)
print(predict[0][0])
if (predict[0][0]>=0.5):pred=int(1)
else: pred=int(0)
print(pred)
## 현재 상황 예측값을 안드로이드 앱에 통신
while True:
#데이터 수신
rc = conn.recv(1024)
rc = rc.decode("utf8").strip()
print(rc)
if rc=="통신중단":
print("Received: " + rc)
receive=rc
#연결 닫기
conn.close()
break
if rc=="통신시작":
a=1
if pred==0:
res = "위급상황"
print("현재상황 : 위급 : " , res)
else:
res = "일반상황"
print("현재상황 : 일반 : " , res)
#클라이언트에게 답을 보냄
conn.sendall(res.encode("utf-8"))
conn.close()
break
s.close()
여기까지가 이 프로젝트에서 내가 담당했던 부분이다.
#후기
이번 프로젝트에서 가장 어려웠던 부분은 데이터 전처리였다.
음성 데이터를 처리하는 과정을 직접 해보는 것은 처음이라 공부하는데 어려움이 있었다.
그래도 나름 이해하며 전처리 과정을 해준 것 같아 뿌듯함이 크다.
그리고 이번에 특히 느낀 점은 데이터의 특성을 잘 맞춰서 특징을 추출해주고,
데이터의 특성을 살릴 수 있는 인공지능 모델을 선택해주어야 좋은 성능의 인공지능을 구현할수 있다는 점이었다.
아쉬웠던 점은, 실제로 녹음된 소리가 만약에 너무 작거나, 학습한 음성 파일과 다른 성질을 가지고 있다면,
어떤 식으로 전처리를 해주어야 인공지능이 바르게 예측할 수 있을 지 의문이 남는다.
그래도 CNN은 공부했던 내용을 잘활용하여 잘 구성한 것 같아 기쁘다.
더 심도있게 공부해보자!
'2021년' 카테고리의 다른 글
| [소프트웨어야 놀자] 대학생 멘토단 '딩가딩가' (0) | 2022.08.01 |
|---|---|
| <Q-learning> 세종 캠퍼스 내 최적 경로 안내 서비스 (0) | 2022.08.01 |
| <머신러닝> 날씨 예보에 따른 관광지 추천 AI 구현 (0) | 2022.07.30 |